A Tale Of Two DBs
Background
Work always manages to throw interesting problems my way and this one was particularly interesting. Our telephone server infrastructure and the associated cloud services were spread across two AWS regions - Singapore & Mumbai. This was primarily done to comply with Indian Data Protection Laws which mandated that customer data associated with some critical areas of business must stay within the country. We had run these two regions as independent entities, with code changes being deployed uniformly across them.
Owing to some changes we had done as part of another unification project, we managed to make the physical servers agnostic of the AWS region. It allowed us to move away from statically assigning servers to a region, and to shift capacity between regions based on demand. As a byproduct of this unification project, we had to reconcile and merge the telephone server data that was currently spread across two databases which were hosted in these two regions.
The Problem
We had two MySQL databases housing telephone server related information in each of our two regions. The goal was to unify the view of data so that it would be the same everywhere. Essentially, the result of running a query on this data should yield the same result regardless of the region it was executed in. We had about 9 tables whose data had to be merged.
There were two impediments that faced us:
- Primary Key(PK) conflicts: PKs were reused across regions, since they were agnostic of each other, which would cause problems if we went for a blind merge.
- Foreign Key(FK) dependency: This is primarily a side effect on the above. Any change in PKs should take the FK relationships into account so that data consistency is maintained at the end of the operation.
The Solution
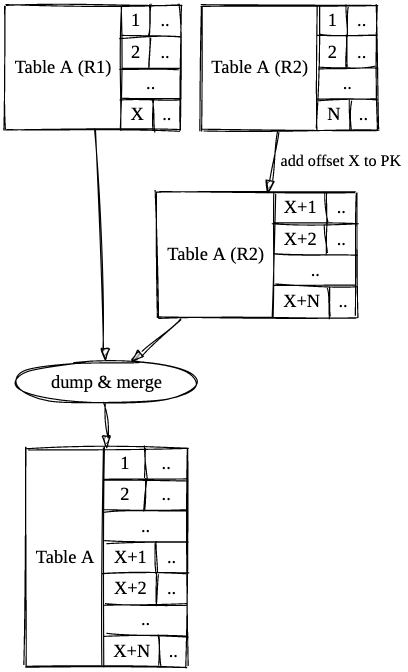
Our databases were slightly asymmetrical such that one region had significantly more data than the other. Adding an offset to the PKs in the smaller DB would ensure that the PKs are continuous and conflict free between the regions. Once the PKs were fixed, we could take a dump and merge the data.
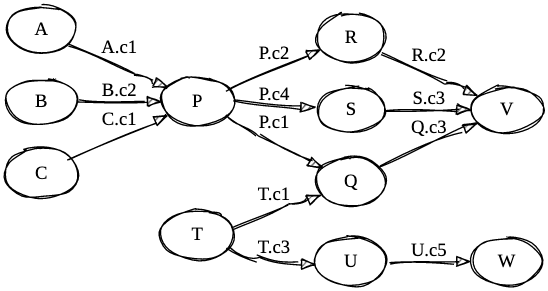
To keep the foreign key relationships intact, the changes would have to be propagated to all the tables that referenced these PK columns. The reference relationship can be obtained using the INFORMATION_SCHEMA.KEY_COLUMN_USAGE table. A simple query like the one detailed in this SO answer would get us all the tables referring to a particular column of a chosen table. When you’re working with multiple tables with multiple relationships, it’s always best to visualize this information to make tracking a little easier. The edges on the graph below denote the column of the referring table which refers to the PK of the referred table.
We prepared the list of queries and scripts to be executed beforehand to minimize downtime and to prevent manual errors. MySQL supports Prepared Statements which is sort of like a DSL that allows us to create (or “prepare”) SQL statements and then execute them. It has basic support for variables, which allows us to write generic SQL queries that can be applied to a lot of tables through the use of variables. This enabled us to cut the canned query size to a large extent.
The Execution
Because of the nature of our system, we could never completely freeze access to the DBs. So we started with the activity during a lean period, when traffic was negligible to minimize outward impacts.
We started by taking a backup of the DBs in both the regions, just to be extra safe. There are a few system level variables that MySQL maintains which dictates the behaviour of the database engine. One of them is foreign_key_checks which indicates whether foreign key constraints would be respected or not. This constraint flag was disabled during the migration, since there was no way to alter the PK without violating the FK relationships. The canned statements were then executed on the smaller DB to fix the PKs and FKs. Once the PK changes were back-propagated, foreign_key_checks were enabled again. Once the changes were made and canned queries were executed in the smaller DB, it was merely a matter of taking a mysqldump from each region and applying it in the other region.
Lessons Learned
- ALWAYS take backups. The more the better. I’ve seen multiple downtimes but messing with production databases and unifying data at this scale remains the single most scariest thing I’ve done to pubDate. So, it’s always good to err on the side of caution, even if it’s a slower and longer path.
- Freeze access to your DBs during data migration: We found that one of the update queries from an automated script had gotten through during the migration phase which resulted in the FK relations getting screwed up. Thankfully, MySQL prevents any updates to a tables once it detects a violation of FK constraints. This allowed us to zero in on the problem and fix it.
- Use prepared statements and canned SQL statements for execution to minimize human error.
Supposedly, the whole process would’ve been a lot easier if we used UUIDs instead of auto incremented ints for our PKs. There’s a wealth of opinions on the web arguing for and against this approach.
Ping me your thoughts and comments.