Wrong Tool For The Job: Concurrent Queues with Aerospike
If all you have is a hammer…
Organizational choices and system architecture sometimes forces you to use sub-optimal tools for a problem. In fact, this is part of the challenge that work throws at you - having to retrofit or abuse tools to get the job done.
If you always had the right set of tools, what fun would life be? This is one such problem.
The Problem
We had an antiquated use case which allowed customers to create a deferred list of jobs. These jobs would then be processed based on API requests from the customer’s end. These lists would usually range from about 100 - 100000 jobs. We also provided a provision whereby the customer could trigger multiple requests in parallel to enable concurrent processing of these jobs. The original design dumped these jobs into MySQL, given that these jobs had to be persisted indefinitely until a trigger was detected.
Stepping back from the nitty-gritty details, you can see that this is in essence a concurrent queue modeled on MySQL. The original implementation was not optimized for our traffic and it suffered from race conditions. We were handling a level of traffic which had caused DB outages in the past, so we did not want to lean on MySQL too much.
Given the scale of the traffic, the criticality of the DB to serve our operations, and the sensitivity of this use-case to latency, it was decided that Aersopike would be used as the primary data store instead of MySQL. As I’d mentioned in my previous post, we use Aerospike A LOT - mostly because it’s blazing fast and scalable, but also because it’s free. We have a data sync mechanism that syncs data from Aerospike to MySQL once the records have been processed.
Data stores were never meant to be used as a job queue and it required some effort to get Aerospike to do the same.
The FCFS Way
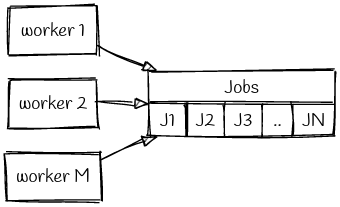
The straightforward way is to implement a First Come First Server (FCFS) system whereby each incoming request would find the first unprocessed job, reserve it, and then proceed with its processing.
In a concurrent environment, whenever there’s a two step process to reserve a job, there’s bound to be race conditions - two requests could come up on the same job, reserve them, and then proceed with the processing of the same job. Even if we were to look past the race condition, this approach would take O(N) time to service to request in the worst case, with N being the total number of jobs in the queue. Ideally, we’d prefer to have a single operation to reserve the job.
The ID Store
To prevent each request traversing the entire length of the job queue we set up a job ID Store which contains the list of all unprocessed jobs.
This was implemented in Aerospike using the list aggregate type, which we used to store the list of unprocessed job IDs. List pop operation (provided by Aerospike) allowed us to get a Job ID while still ensuring isolation between requests. In addition, the jobs were indexed based on job IDs for faster access.
Thus each request would first pop off from the ID store and select the corresponding job from the jobs set. This has the dual benefit of avoiding race conditions by leaning on the storage engine to ensure isolation, and decreasing the worst case job assignment complexity to O(1).
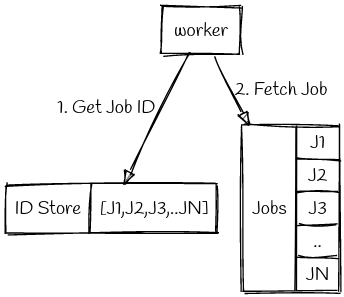
The only downside here is the Aerospike record limit. Each record in Aerospike is like a row in a SQL DB and Aerospike has a (configurable) limit on the size of each record. Unlucky for me, this limit was set at 128KB in our system. If we assume each job ID to be 8B, then we can accommodate only 16000 IDs per record.
Can we do better?
The Token Store Optimization
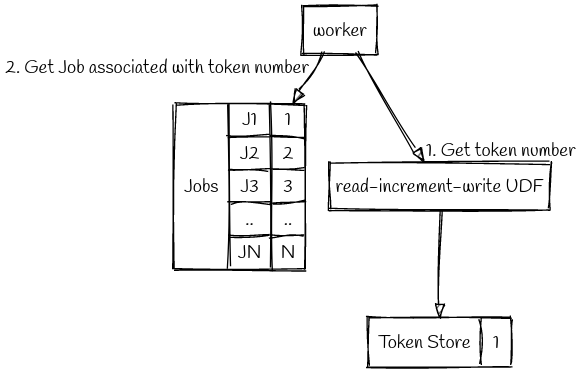
We had to store the list of job IDs because they’re usually non-contiguous numeric identifiers. We can forego this list, if we assign sequential token IDs to each job. This indexed field provides an alternative way to refer to jobs within a set. The ID Store, which we’ll now call the Token Store, will contain the token ID of the next job to be processed. You can think of it as a pointer to the job queue. This will help us tide over the record size limitations.
To reserve a job, a request would get the current token ID in the Token Store, fetch the corresponding record from the job set and then increment the token value so that it points to the next unprocessed job.
While this looks efficient, it brings back the inevitable race condition - two jobs could read the same value and reserve the same job. What we need is an atomic operation to deal with the token ID.
Aersopike provides the facility to define User Defined Functions(UDF) in Lua which allows us to define new functions that are guaranteed to be atomic by the storage engine. So, we defined a UDF to implement the read-increment-write operation which would read the token value, increment it, write the incremented value, and return the old value. Thus, each incoming request would invoke the read-increment-write UDF on Token Store to get the token ID, and would use this ID to get the corresponding job.
We’ve thus managed to stick to O(1) for job assignment while cutting down the space requirement of the list.
Drawbacks
The primary downside is that we have no way to ensure fault tolerance. If a request, which reserved a job, dies then we have no way to put that job back into the pool of reserved jobs. Thus the optimization might not be useful in the general context, but was acceptable for our specific use-case.
Alternatives
Using a SQL DB
Aerospike is a NoSQL datastore and thus do not provide the rich set of operations made available by SQL. As outlined in this answer on Database Administrator, SQL databases like MySQL enables us to use a combination of Transactions and SELECT FOR UPDATE to achieve the same result, albeit with a slightly higher performance penalty.
We couldn’t use it for our use-case as our MySQL DB was far too precious to be put under heavy load from such a bursty workflow.
Using a Message Queue
A simple persistent message queue like Beanstalkd would’ve been a perfect fit for this problem. Message Queues have the concept of tubes, which provides a high level way to group messages, which could be used for organizing jobs from different customers into different tubes. They also provide facilities like delays, whereby a job is put back into the queue if the reserved consumer has not responded withing a stipulated time frame, which would take care of the fault tolerance aspect.
We couldn’t use this solution because our services had some design decisions baked in, which made integrating a message queue into the flow a non-trivial exercise.
Lessons Learned
- Your problem does not exist in a vacuum. Your possible solutions would be constrained by the environment you operate in.
- Technical decisions, especially in the context of services, have long term repercussions that would influence the enhancements and modifications that could be carried out on it.
- Be realistic about the effort involved in implementing the perfect solution, in view of the time constraints - job Queues would’ve been perfect, but an optimized Aerospike setup was the next best option.
- Know when to stop. Optimization are an unending rabbit hole.
- Prefer clarity over cleverness wherever possible.
This blog post is my explanation for future maintainers of my code as to how things reached the state they are in now. I did what had to be done. :P
Ping me your thoughts and comments.
Check out Aerospike and Beanstalkd, if you haven’t already!
All diagrams were created using Sketchviz